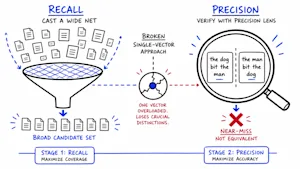
Redis research warns that fine-tuning RAG embedding models for “compositional sensitivity” can quietly harm general retrieval, dropping accuracy up to 40% on production mid-size models. The issue: structural meaning shifts like negation and role reversals can end up near-identical in embedding space, while common fine-tuning metrics miss it. Agentic pipelines are especially vulnerable.
The most costly enterprise AI failures may produce no errors, no red dashboards, and no alerts—yet deliver confident, consistently wrong outputs. The issue isn’t the model’s benchmark performance, but “context decay,” orchestration drift, stale retrieval, and silent partial failures across infrastructure and workflows. Fixing it requires behavioral telemetry and intent-based stress tests, not just uptime monitoring.
Your news, in seconds
Get the Beige app — every story in 60 words, updated hourly. Free on iOS & Android.
Swipe through stories, personalise your feed, and save articles for later — all on the app.