Pinecone says the classic RAG-to-vector pipeline fails for agentic AI, where tasks require reassembling context across sources and sessions. The company’s Nexus shifts reasoning to a compilation stage, creating persistent, task-specific knowledge artifacts, plus KnowQL for declarative agent queries. An internal benchmark claims a 98% token reduction, aiming at deterministic grounding and governance-ready outputs.
LlamaIndex’s CEO Jerry Liu argues the “scaffolding” developers once needed for LLM apps—indexing layers, retrieval pipelines, and complex orchestration—is collapsing as models and tools improve. In this shift, he says the real differentiator is context: better parsing of file formats and agentic document understanding like OCR. He also warns builders to stay modular as models change and parts of stacks will be replaced.
Your news, in seconds
Get the Beige app — every story in 60 words, updated hourly. Free on iOS & Android.
VB Pulse data for Q1 2026 shows enterprises stopped adding new retrieval layers and instead rebuilt what they already had. Hybrid retrieval intent tripled to 33.3%, while 22% report having no production RAG. Evaluation budgets slid as retrieval optimization surged, driven by reliability and access-control needs that break older “vector only” designs at agentic scale.
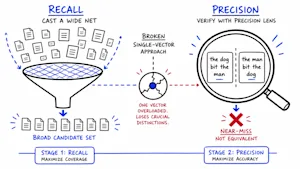
Redis research warns that fine-tuning RAG embedding models for “compositional sensitivity” can quietly harm general retrieval, dropping accuracy up to 40% on production mid-size models. The issue: structural meaning shifts like negation and role reversals can end up near-identical in embedding space, while common fine-tuning metrics miss it. Agentic pipelines are especially vulnerable.
Swipe through stories, personalise your feed, and save articles for later — all on the app.